Technical overview
We publish climbing content ("data") in two forms, human-readable and machine-readable. Having two representations of the same data enables us to address multiple community needs.
Benefits of a climbing route wiki:
We're hoping by creating a useful and easy-to-use wiki with a powerful "search engine" that provides value to our users, we can build a community of editors that will help us identify inaccuracies and improve the underlying data.
Benefits of open access to machine-readable climbing data:
- Enable independent developers to build on and enrich the existing ecosystem.
- Provide data science students with much needed datasets.
- Increase the efficiency of public research related to climbing.
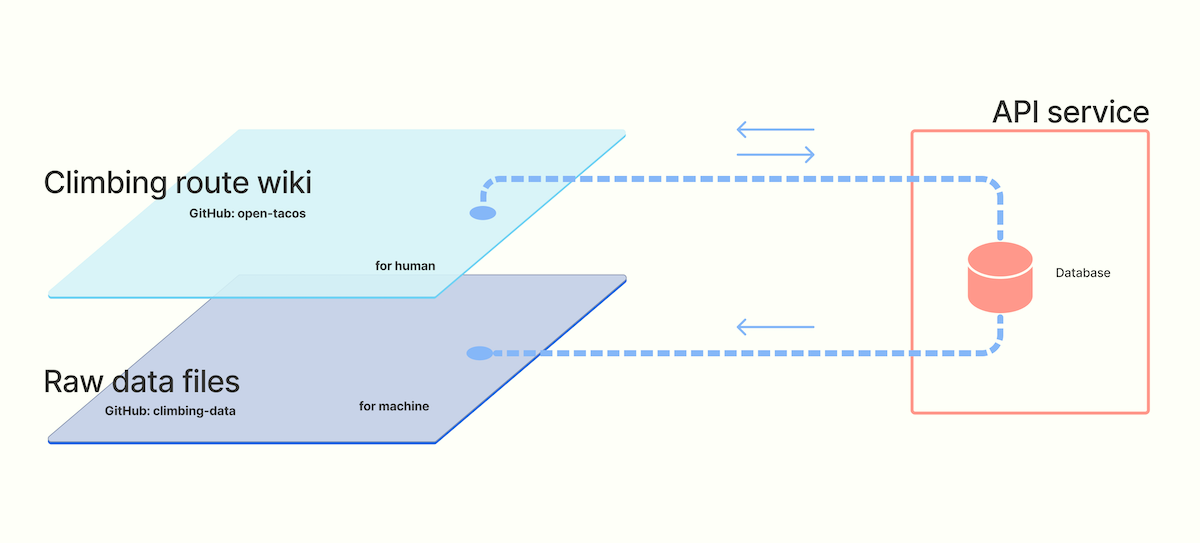
Climbing route wiki
Inspired by Wikipedia and OpenStreetMap, the OpenBeta Climbing Catalog web application provides the climbing community with a searchable catalog of climbing routes.
- Climb Search API
- Photo sharing and climb tagging
- Work-in-progress: Collaborative editing.
Live site: https://openbeta.io
Source code: https://github.com/openbeta/open-tacos
Climbing data
Climbing datasets in CSV, jsonlines, and Python pickle format.
Source code: https://github.com/openbeta/climbing-data
API service
A GraphQL-based API that provides data for the OpenBeta Climbing Catalog. We plan to open the API to public at some point in 2022. Be sure to subscribe to the newsletter.
Source code: https://github.com/openbeta/openbeta-graphql
Climbing grade library (aka "SandBag")
A JavaScript/TypeScript library for doing grade validation, conversion and comparision.
Source code: https://github.com/OpenBeta/sandbag